
Code Interpreter 真的是挺强大的,今天又让它帮我做了个事情:按照标点符号重新整理Whisper识别后的字幕时间戳。
我经常用WhisperX来生成字幕,它的优点就是会按照自然句子分割,这样每一个句子得到的是完整的句子,让GPT翻译时结果就好很多。…
IT技术
(
twitter.com
)
Code Interpreter 真的是挺强大的,今天又让它帮我做了个事情:按照标点符号重新整理Whisper识别后的字幕时间戳。
我经常用WhisperX来生成字幕,它的优点就是会按照自然句子分割,这样每一个句子得到的是完整的句子,让GPT翻译时结果就好很多。
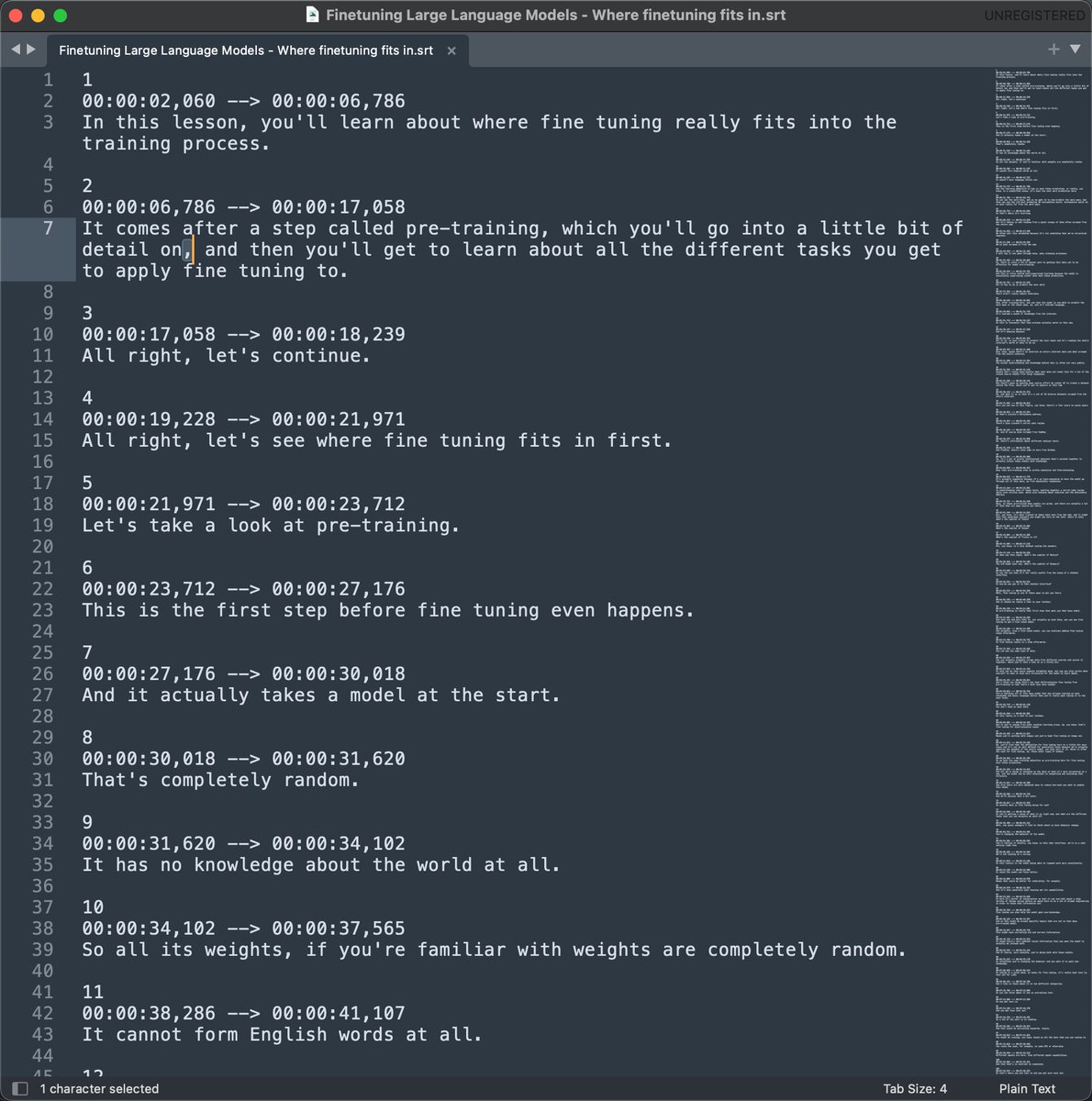
但是有一个问题,有时候一个句子太长,例如图1的第二个字幕,这样在显示字幕时就太占地方了。最好是句子很长的时候,就按照逗号再分割一下。
好在WhisperX在生成时,会同时生成一个JSON文件(参考图2),包含了每一个单词的开始时间和结束时间,所以理论上来说我可以解析JSON文件,重新生成字幕文件。
不过我觉得自己写这个代码太麻烦了,于是我想为什么不用 Code Interpreter 呢?
于是把JSON文件上传给Code Interpreter,让它帮我重新生成srt字幕文件,它很快就完成了(参考图3),只是有个小bug,不过指正后马上修复了。
最终结果就是我想要的,第二个长句子拆分成了短句子(参考图4)。
完整对话可以参考:
https://t.co/CTFyshEE0T
点击图片查看原图

点击图片查看原图

点击图片查看原图

点击图片查看原图

