
刚深扒了一下 MiroThinker 1.5,他们这套 Agent 压缩方式有点邪门,但看懂了觉得确实有用。
核心解决的是「怎么在 256K 上下文里塞进去 400 次 Tool Use」的问题。
他们做了一个极其大胆的操作:对ReAct历史上 think-action-observation 中的的 Observation(工具返回结果)进行物理掩码。
除了最近 K
时政
(
twitter.com
)
刚深扒了一下 MiroThinker 1.5,他们这套 Agent 压缩方式有点邪门,但看懂了觉得确实有用。
核心解决的是「怎么在 256K 上下文里塞进去 400 次 Tool Use」的问题。
他们做了一个极其大胆的操作:对ReAct历史上 think-action-observation 中的的 Observation(工具返回结果)进行物理掩码。
除了最近 K 轮保留原文,之前的几百轮 Tool Result 全部替换成一句 "Tool result is omitted to save tokens"。但是完整保留了所有的
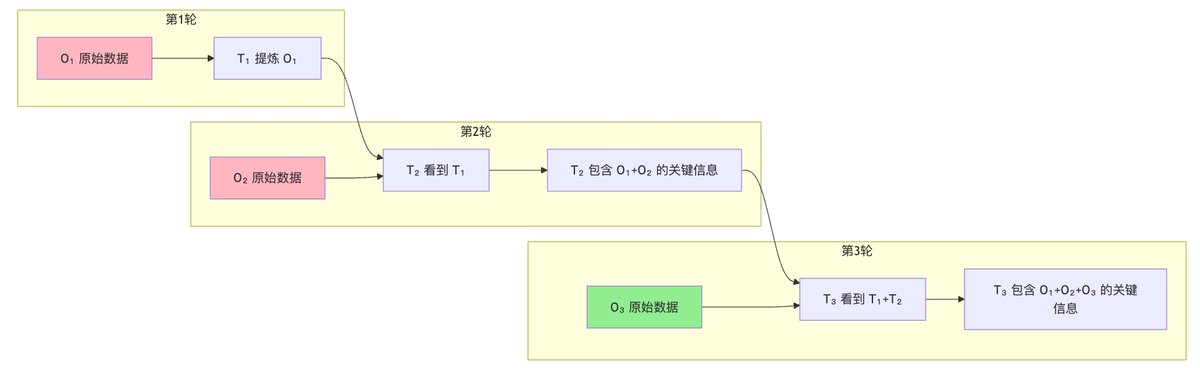
这里面有一个非常反直觉的地方,这个 agent 本身就是在做 deep research,那他只留最近 K 轮,也就是 5 轮的原文,前面都没有了,还怎么能回答问题。
这就有一个非常隐晦但关键的前提:只要 Thought 足够密,它其实就是在无限逼近 Summary。
每一次 Thought 的生成,本质上都是模型对当前 Observation 的一次信息切片。T1 产生时已经把 O1 里的关键数据“吃”进脑子了。
虽然 O1 被替换成了占位符,但 T1 还在。T1 就成了 O1 的“信息压缩包”。不需要额外挂一个 Summary Agent,这条完整的 Thought 链,本身就是一份不断增量更新的、高保真的「动态摘要」。
点击图片查看原图

