
Cursor 刚发表了篇文章:《Dynamic context discovery》
之前 Manus 的 Peak 在访谈里面说:
> 所以 Peak
IT技术
(
twitter.com
)
Cursor 刚发表了篇文章:《Dynamic context discovery》https://t.co/O9trD8o1gy(译文:https://t.co/O1ODpZz3YV),讲述了他们上下文管理的秘密。
之前 Manus 的 Peak 在访谈里面说:
> 所以 Peak 说当他们读到一些模型公司发布的研究博客时,心情是“既开心又无奈”。开心是因为这些博客验证了他们的方向,无奈是因为博客里写的东西,基本都是他们早就在做的。
Cursor 这篇文章又曾侧面印证了这个观点😂,不过也不能说 Cursor 是在抄袭 Manus 的技术,只能说 AI Agent 的最佳实践,就是怎么管理好上下文,而管理好上下文,就离不开文件系统。
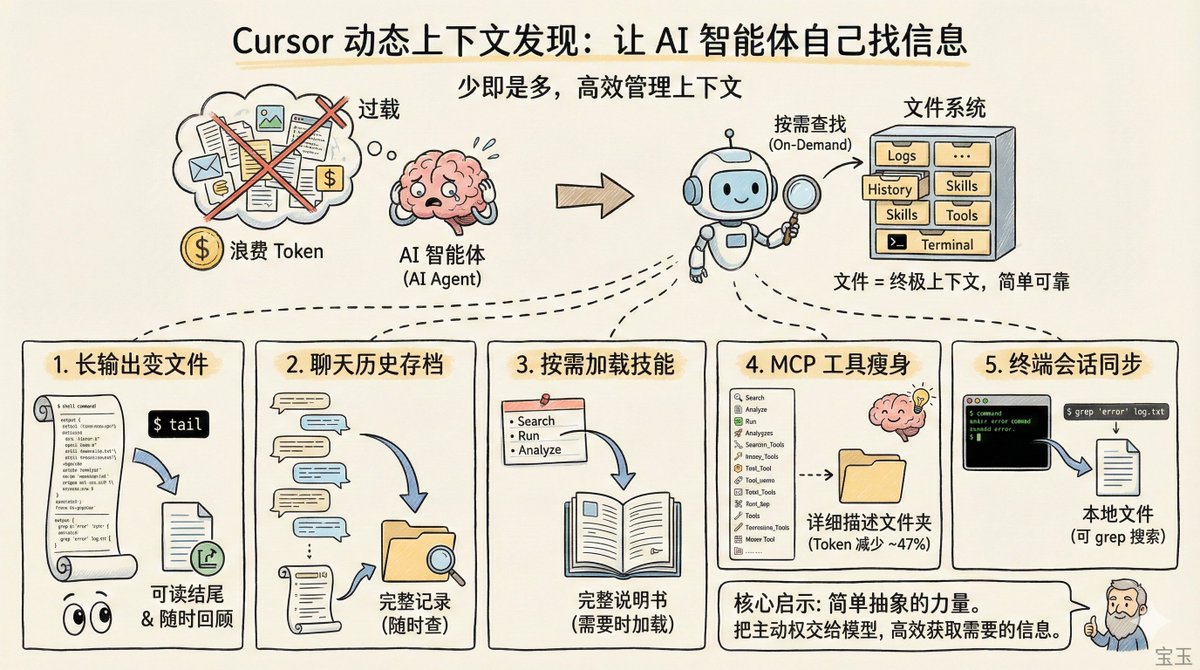
言归正传,Cursor 这篇文章讲的是“动态上下文发现”,核心就是上下文管理。
给 AI 的上下文,不是越多越好,很多人用 AI,生怕 AI 不知道,怕 AI 记不住,恨不得把整个项目的文档、历史记录、工具说明一股脑全塞进去。
但随着模型变得越来越聪明,预先塞太多信息反而帮倒忙。一来浪费 token(上下文窗口是有限的),二来信息太杂可能干扰模型判断。就像你给一个能干的下属布置任务,不需要把公司所有制度文件都打印出来放他桌上,他需要什么,自己会去查。
这就是 Cursor 提出的"动态上下文发现"(Dynamic Context Discovery)模式:别急着把信息塞给模型,而是让模型在需要的时候自己去找。
【1】让 AI 自己找需要的信息
听起来简单,但具体怎么做呢?Cursor 分享了五个他们实际在用的优化手段,每个都挺巧妙。
场景一:长输出变成文件
问题是什么?当 AI 调用外部工具(比如运行一个 shell 命令或者调用 MCP 服务),返回的结果可能很长——一大串日志、一整个网页的内容。常见做法是截断,只保留一部分。但截掉的那部分,说不定正好是后面要用的关键信息。
Cursor 的做法是:把长输出写成文件,然后给 AI 一个读文件的能力。AI 可以先用 tail 命令看看结尾,觉得需要再往前读。这样既不会塞满上下文,也不会丢信息。
场景二:聊天历史变成可查档案
当对话太长,超过上下文窗口限制时,Cursor 会触发一个"总结"步骤,把之前的内容压缩成摘要,给 AI 一个"新的起点"。
但压缩是有损的。重要细节可能在总结过程中丢失,导致 AI"失忆"。Cursor 的办法是把完整的聊天记录存成文件。AI 拿到的是摘要,但如果它意识到"这里好像漏了什么",可以自己去翻原始记录找回来。
这就像是你给员工发了一份会议纪要,但完整的会议录音也存着——有疑问随时可以回溯。
场景三:按需加载技能
Cursor 支持一种叫"Agent Skills"的扩展机制,本质上是告诉 AI 怎么处理特定领域任务的说明书。这些说明书可以有很多,但没必要每次都全部加载。
Cursor 的做法是只在系统提示里放一个"目录"——技能的名字和简短描述。AI 真正需要某个技能时,再用搜索工具把完整说明拉进来。就像你不会把整个图书馆背在身上,只带个索引卡片就够了。
场景四:MCP 工具的瘦身术
这个场景数据最有说服力。MCP 是一种让 AI 连接外部服务的标准协议,现在很火。问题是,有些 MCP 服务器提供几十个工具,每个工具的描述都很长,全塞进上下文窗口很占地方。更尴尬的是,大部分工具在一次任务中根本用不到。
Cursor 的优化方式是:只在提示词里放工具的名字,完整描述同步到一个文件夹。AI 需要用某个工具时,再去查具体怎么用。
效果怎么样?他们做了 A/B 测试,在调用 MCP 工具的场景下,这个策略减少了 46.9% 的 Token 消耗。接近一半的成本省下来了。
还有个附带好处:如果某个 MCP 服务需要重新认证,以前 AI 就会"忘记"这些工具的存在,用户一头雾水。现在 AI 能主动提醒用户"喂,你的 XX 服务需要重新登录了"。
关于 MCP 工具的优化,Anthropic 官方有一篇文章《Code execution with MCP: Building more efficient agents》https://t.co/Opk5JC6Fvb,思路也是类似的,推荐看看。
场景五:终端会话也是文件
用过 AI 编程工具的人都知道,有时候你想问"我刚才那个命令为什么失败了",但 AI 根本不知道你运行过什么命令。你得手动把终端输出复制粘贴给它。
Cursor 现在把集成终端的输出自动同步到本地文件系统。AI 可以直接"看到"你的终端历史,需要的话还能用 grep 搜索特定内容。对于那些跑了很久的服务日志,这个功能特别实用。
【2】为什么是"文件"
你可能注意到了,Cursor 这五个优化有个共同点:都是把东西变成文件。
为什么是文件而不是别的抽象?
Cursor 的说法是:
> 我们不确定未来 LLM 工具的最佳接口是什么,但文件是一个简单、强大的基础单元,比发明一套新抽象要安全得多。
这个思路和 Manus 的理念不谋而合。Peak 在他们的技术博客《AI 智能体的上下文工程:构建 Manus 的经验教训》https://t.co/jTT5bEtCaU 里专门讲过:他们把文件系统当作"终极上下文"——容量无限、天然持久、而且 AI 自己就能操作。
Peak 举的例子很形象:一个网页的内容可以从上下文里删掉,只要 URL 还在,AI 随时能把内容找回来。一个文档的全文可以省略,只要文件路径在,需要时再读取就行。这种"可恢复的压缩",比简单的截断或删除聪明多了。
【3】几点思考
一个启示是:上下文工程的核心可能不是"怎么塞更多信息",而是"怎么让模型高效获取需要的信息"。随着模型能力提升,把主动权交给模型是一个趋势。
另一个启示是简单抽象的力量。在技术领域,我们经常迷恋复杂精巧的设计。但文件这个例子提醒我们:那些经过时间检验的简单抽象,往往比看起来高级的新发明更耐用。
模型够聪明的时候,少塞点东西、让它自己找,可能比硬塞一堆效果更好。有时候,less is more。
点击图片查看原图

