2
1
0

看鸭哥写的:《AI 工程的真实代价:从 Claude Code 泄露源码看新模型接入的工程现实》
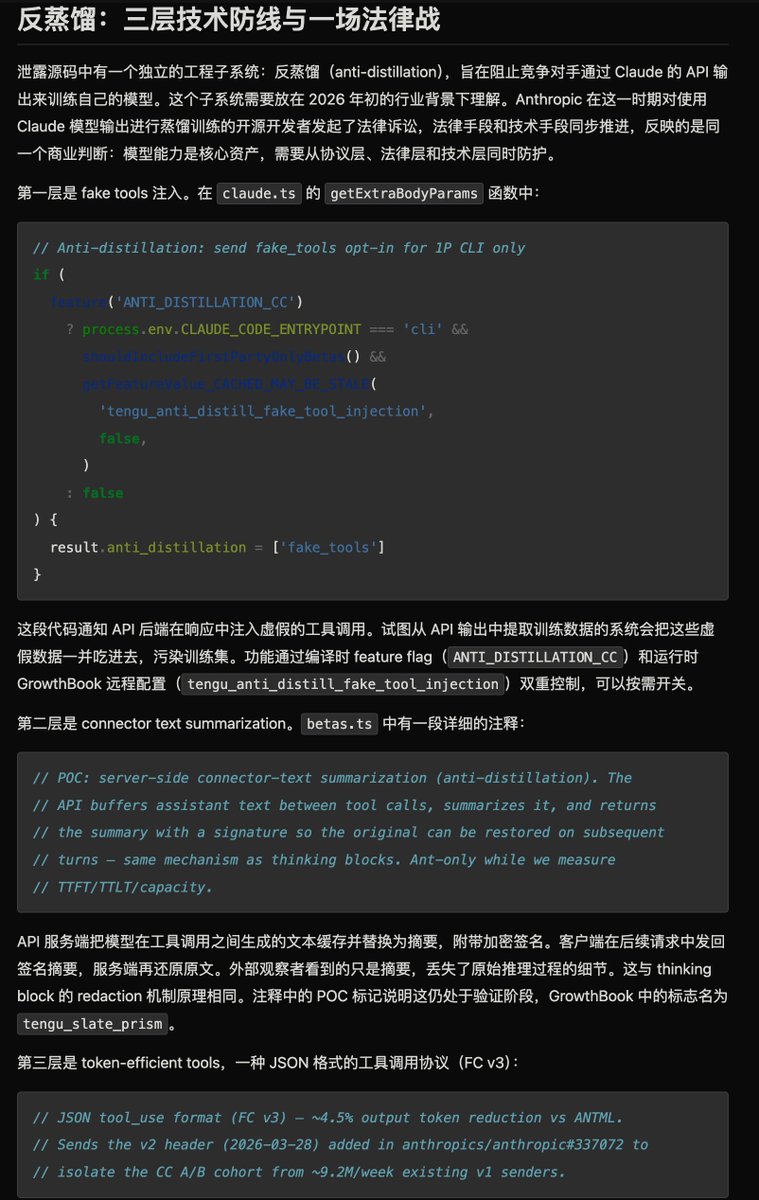
里面提到了 Anthropic 在 Claude Code 里埋了三层反蒸馏机制,专门防竞争对手用 API 输出来训练自己的模型。泄露的源码把这套系统完整暴露了出来。
第一层:往输出里掺假。API
IT技术
(
yage.ai
)
由
宝玉
提交
看鸭哥写的:《AI 工程的真实代价:从 Claude Code 泄露源码看新模型接入的工程现实》
https://t.co/Cz5XBMXnCk
里面提到了 Anthropic 在 Claude Code 里埋了三层反蒸馏机制,专门防竞争对手用 API 输出来训练自己的模型。泄露的源码把这套系统完整暴露了出来。
第一层:往输出里掺假。API 返回结果时,服务端会混入一些虚假的工具调用数据。正常用户完全不受影响,服务端会帮你过滤掉。但如果有人批量抓取 API 输出去训练模型,这些假数据会一起被吃进训练集,污染模型质量。
第二层:把推理过程藏起来。Claude 在工具调用之间会产生中间推理文本,比如"我先读这个文件,再检查语法"。这些细节对蒸馏训练价值很高,因为它暴露了模型怎么思考。这一层把中间文本替换为一句摘要加密签名,下一轮对话时客户端拿签名换回原文。外部观察者只能看到摘要,完整推理链拿不到。
第三层:协议隔离。Claude Code 用一种新的 JSON 协议格式跟 API 通信,带独立的版本标记,跟每周 920 万次的普通 API 请求在统计上隔离开。服务端可以对不同群体做差异化处理,也让竞争对手无法简单伪装成 Claude Code 来获取特殊待遇。附带好处是省了大约 4.5% 的输出 token。
点击图片查看原图
Markdown支持
评论加载中...
您可能感兴趣的:
3
131
130
130
8
653
652
652
18
485
484
484
19
227
226
226

